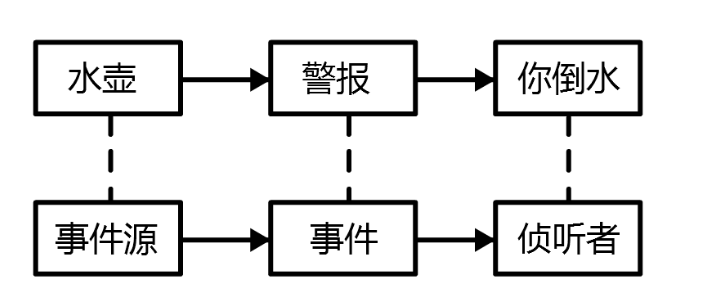
并发与竞争
1、应用层的锁和内核中的锁区别
1-1、特性
1-1-1、 内核锁(Kernel Locks)
- 作用:内核锁用于保护内核数据结构,防止多个内核线程或进程同时访问和修改这些数据结构,从而避免数据不一致或竞争条件。
- 类型:
- 自旋锁(Spinlock):当一个线程试图获取已经被占用的自旋锁时,它会不断循环(自旋)直到锁可用。适用于持有时间短的场景。
- 互斥锁(Mutex):当一个线程试图获取已经被占用的互斥锁时,它会被阻塞,直到锁可用。适用于持有时间较长的场景。
- 读写锁(Read-Write Lock):允许多个读操作同时进行,但写操作是独占的。适用于读多写少的场景。
- 使用场景:内核锁主要用于内核空间,保护内核数据结构,确保内核的稳定性和一致性。
1-1-2、 应用层锁(Application-Level Locks)
- 作用:应用层锁用于保护应用程序中的共享数据,防止多个线程或进程同时访问和修改这些数据,从而避免数据不一致或竞争条件。
- 类型:
- 互斥锁(Mutex):类似于内核中的互斥锁,用于保护共享资源,确保同一时间只有一个线程可以访问。
- 读写锁(Read-Write Lock):允许多个读操作同时进行,但写操作是独占的。
- 条件变量(Condition Variable):用于线程间的通信,允许一个线程等待某个条件成立后再继续执行。
- 信号量(Semaphore):用于控制对共享资源的访问,可以是二进制信号量(类似于互斥锁)或多级信号量。
- 使用场景:应用层锁主要用于用户空间,保护应用程序中的共享数据,确保应用程序的稳定性和一致性。
1-1-3、 关系
- 隔离性:内核锁和应用层锁在功能上是隔离的。内核锁用于保护内核数据结构,而应用层锁用于保护用户空间的数据。
- 互操作:虽然内核锁和应用层锁在功能上是隔离的,但在某些情况下,它们可能会相互影响。例如,当一个线程在内核空间中持有锁时,如果该线程被调度到用户空间执行应用层代码,应用层代码可能会尝试获取锁,这需要确保锁的粒度和使用方式不会导致死锁或其他并发问题。
- 性能考虑:内核锁和应用层锁的性能特性不同。内核锁通常更高效,但只能在内核空间中使用;应用层锁则可以在用户空间中使用,但可能需要更多的系统调用来实现。
总结
内核锁和应用层锁虽然在功能和使用场景上有明显的区别,但它们都是为了保护共享数据,避免并发问题。在设计并发程序时,需要根据具体的需求选择合适的锁类型,并确保锁的使用不会导致死锁或其他并发问题。
2、自旋锁
自旋锁(Spinlock)是一种同步机制,用于保护共享资源,确保同一时间只有一个线程可以访问该资源。自旋锁的基本思想是当一个线程试图获取已经被占用的锁时,它会不断循环(自旋)直到锁可用。自旋锁适用于持有时间短的场景,因为它不会使线程进入睡眠状态,从而避免了线程切换的开销。
在不同的操作系统和编程环境中,自旋锁的API可能会有所不同。以下是一些常见的操作系统和编程环境中的自旋锁API示例:
2-1、api
2-1-1、 Linux 内核中的自旋锁
在Linux内核中,自旋锁的API定义在<linux/spinlock.h>头文件中。以下是一些常用的自旋锁API:
定义自旋锁:
1
spinlock_t my_lock;
初始化自旋锁:
1
spin_lock_init(&my_lock);
获取自旋锁:
1
spin_lock(&my_lock);
释放自旋锁:
1
spin_unlock(&my_lock);
带中断保护的自旋锁:
1
2
3
4unsigned long flags;
spin_lock_irqsave(&my_lock, flags);
// 临界区代码
spin_unlock_irqrestore(&my_lock, flags);
2-1-2、 POSIX 线程(Pthreads)中的自旋锁
在POSIX线程中,自旋锁的API定义在<pthread.h>头文件中。以下是一些常用的自旋锁API:
定义自旋锁:
1
pthread_spinlock_t my_lock;
初始化自旋锁:
1
pthread_spin_init(&my_lock, PTHREAD_PROCESS_PRIVATE);
获取自旋锁:
1
pthread_spin_lock(&my_lock);
释放自旋锁:
1
pthread_spin_unlock(&my_lock);
销毁自旋锁:
1
pthread_spin_destroy(&my_lock);
2-1-3、 C++11 标准库中的自旋锁
在C++11标准库中,并没有直接提供自旋锁的实现,但可以使用std::atomic来实现自旋锁。以下是一个简单的自旋锁实现示例:
1 |
|
示例代码
以下是一个使用Linux内核自旋锁的简单示例:
1 |
|
在这个示例中,spin_lock和spin_unlock用于保护对shared_resource的访问,确保同一时间只有一个线程可以修改该资源。
总结
自旋锁的API在不同的操作系统和编程环境中有所不同。在Linux内核中,自旋锁的API定义在<linux/spinlock.h>中;在POSIX线程中,自旋锁的API定义在<pthread.h>中;在C++11标准库中,可以使用std::atomic来实现自旋锁。选择合适的自旋锁API取决于具体的编程环境和需求。
3、原子操作
某个值的原子操作
原子操作(Atomic Operations)是一种在多线程环境中对共享数据进行无锁操作的技术,确保操作的原子性,即操作是不可分割的,不会被其他线程中断。原子操作通常用于实现锁-free 数据结构或提高并发性能。以下是一些常见操作系统和编程环境中的原子操作API示例。
3-1、api
3-1-1、 Linux 内核中的原子操作
在Linux内核中,原子操作的API定义在<linux/atomic.h>头文件中。以下是一些常用的原子操作API:
定义原子变量:
1
atomic_t my_atomic_var;
初始化原子变量:
1
atomic_set(&my_atomic_var, 0);
读取原子变量的值:
1
int value = atomic_read(&my_atomic_var);
增加原子变量的值:
1
atomic_inc(&my_atomic_var);
减少原子变量的值:
1
atomic_dec(&my_atomic_var);
增加并返回新值:
1
int new_value = atomic_add_return(5, &my_atomic_var);
减少并返回新值:
1
int new_value = atomic_sub_return(5, &my_atomic_var);
比较并交换(Compare and Swap, CAS):
1
int old_value = atomic_cmpxchg(&my_atomic_var, old, new);
3-1-2、 POSIX 线程(Pthreads)中的原子操作
在POSIX线程中,原子操作的API定义在<stdatomic.h>头文件中。以下是一些常用的原子操作API:
定义原子变量:
1
atomic_int my_atomic_var;
初始化原子变量:
1
atomic_init(&my_atomic_var, 0);
读取原子变量的值:
1
int value = atomic_load(&my_atomic_var);
存储值到原子变量:
1
atomic_store(&my_atomic_var, 5);
增加原子变量的值:
1
atomic_fetch_add(&my_atomic_var, 1);
减少原子变量的值:
1
atomic_fetch_sub(&my_atomic_var, 1);
比较并交换(Compare and Swap, CAS):
1
2
3int expected = 0;
int desired = 1;
int result = atomic_compare_exchange_strong(&my_atomic_var, &expected, desired);
3-1-3、 C++11 标准库中的原子操作
在C++11标准库中,原子操作的API定义在<atomic>头文件中。以下是一些常用的原子操作API:
定义原子变量:
1
std::atomic<int> my_atomic_var;
初始化原子变量:
1
my_atomic_var = 0;
读取原子变量的值:
1
int value = my_atomic_var.load();
存储值到原子变量:
1
my_atomic_var.store(5);
增加原子变量的值:
1
my_atomic_var.fetch_add(1);
减少原子变量的值:
1
my_atomic_var.fetch_sub(1);
比较并交换(Compare and Swap, CAS):
1
2
3int expected = 0;
int desired = 1;
bool success = my_atomic_var.compare_exchange_strong(expected, desired);
示例代码
以下是一些使用不同环境中的原子操作的示例代码。
Linux 内核中的原子操作示例
1 |
|
POSIX 线程中的原子操作示例
1 |
|
C++11 标准库中的原子操作示例
1 |
|
总结
原子操作的API在不同的操作系统和编程环境中有所不同。在Linux内核中,原子操作的API定义在<linux/atomic.h>中;在POSIX线程中,原子操作的API定义在<stdatomic.h>中;在C++11标准库中,原子操作的API定义在<atomic>中。选择合适的原子操作API取决于具体的编程环境和需求。原子操作可以显著提高并发程序的性能,特别是在多线程环境中。
4、互斥锁
互斥锁(Mutex)是一种同步机制,用于保护共享资源,确保同一时间只有一个线程可以访问该资源。互斥锁的基本思想是当一个线程试图获取已经被占用的互斥锁时,它会被阻塞,直到锁可用。互斥锁适用于持有时间较长的场景,因为它允许线程在等待锁时进入睡眠状态,从而避免了线程切换的开销。
4-1、api
以下是不同操作系统和编程环境中的互斥锁API示例:
4-1-1、 Linux 内核中的互斥锁
在Linux内核中,互斥锁的API定义在<linux/mutex.h>头文件中。以下是一些常用的互斥锁API:
定义互斥锁:
1
struct mutex my_mutex;
初始化互斥锁:
1
mutex_init(&my_mutex);
获取互斥锁:
1
mutex_lock(&my_mutex);
释放互斥锁:
1
mutex_unlock(&my_mutex);
尝试获取互斥锁:
1
2
3
4
5if (mutex_trylock(&my_mutex)) {
// 成功获取锁
} else {
// 获取锁失败
}
4-1-2、 POSIX 线程(Pthreads)中的互斥锁
在POSIX线程中,互斥锁的API定义在<pthread.h>头文件中。以下是一些常用的互斥锁API:
定义互斥锁:
1
pthread_mutex_t my_mutex;
初始化互斥锁:
1
pthread_mutex_init(&my_mutex, NULL);
获取互斥锁:
1
pthread_mutex_lock(&my_mutex);
释放互斥锁:
1
pthread_mutex_unlock(&my_mutex);
销毁互斥锁:
1
pthread_mutex_destroy(&my_mutex);
尝试获取互斥锁:
1
2
3
4
5if (pthread_mutex_trylock(&my_mutex) == 0) {
// 成功获取锁
} else {
// 获取锁失败
}
4-1-3、C++11 标准库中的互斥锁
在C++11标准库中,互斥锁的API定义在<mutex>头文件中。以下是一些常用的互斥锁API:
定义互斥锁:
1
std::mutex my_mutex;
获取互斥锁:
1
my_mutex.lock();
释放互斥锁:
1
my_mutex.unlock();
尝试获取互斥锁:
1
2
3
4
5if (my_mutex.try_lock()) {
// 成功获取锁
} else {
// 获取锁失败
}使用锁保护代码块:
1
2std::lock_guard<std::mutex> lock(my_mutex);
// 临界区代码
示例代码
以下是一些使用不同环境中的互斥锁的示例代码。
Linux 内核中的互斥锁示例
1 |
|
POSIX 线程中的互斥锁示例
1 |
|
C++11 标准库中的互斥锁示例
1 |
|
总结
互斥锁的API在不同的操作系统和编程环境中有所不同。在Linux内核中,互斥锁的API定义在<linux/mutex.h>中;在POSIX线程中,互斥锁的API定义在<pthread.h>中;在C++11标准库中,互斥锁的API定义在<mutex>中。选择合适的互斥锁API取决于具体的编程环境和需求。互斥锁可以有效地保护共享资源,避免并发问题,但在使用时需要注意避免死锁和其他并发问题。
5、信号量
信号量(Semaphore)是一种同步机制,用于控制对共享资源的访问,可以是二进制信号量(类似于互斥锁)或多级信号量。信号量通过维护一个计数器来管理资源的访问权限,允许多个线程或进程同时访问共享资源,但数量受限于信号量的初始值。
5-1、api
以下是不同操作系统和编程环境中的信号量API示例:
5-1-1. Linux 内核中的信号量
在Linux内核中,信号量的API定义在<linux/semaphore.h>头文件中。以下是一些常用的信号量API:
定义信号量:
1
struct semaphore my_semaphore;
初始化信号量:
1
sema_init(&my_semaphore, count);
获取信号量:
1
down(&my_semaphore);
释放信号量:
1
up(&my_semaphore);
尝试获取信号量:
1
2
3
4
5if (down_trylock(&my_semaphore) == 0) {
// 成功获取信号量
} else {
// 获取信号量失败
}
5-1-2、 POSIX 线程(Pthreads)中的信号量
在POSIX线程中,信号量的API定义在<semaphore.h>头文件中。以下是一些常用的信号量API:
定义信号量:
1
sem_t my_semaphore;
初始化信号量:
1
sem_init(&my_semaphore, 0, count);
获取信号量:
1
sem_wait(&my_semaphore);
释放信号量:
1
sem_post(&my_semaphore);
销毁信号量:
1
sem_destroy(&my_semaphore);
尝试获取信号量:
1
2
3
4
5if (sem_trywait(&my_semaphore) == 0) {
// 成功获取信号量
} else {
// 获取信号量失败
}
5-1-3、 C++11 标准库中的信号量
C++11标准库中并没有直接提供信号量的实现,但可以使用std::counting_semaphore(C++20引入)或通过std::mutex和std::condition_variable来实现信号量。以下是使用std::counting_semaphore的示例:
定义信号量:
1
std::counting_semaphore<5> my_semaphore(5); // 初始值为5
获取信号量:
1
my_semaphore.acquire();
释放信号量:
1
my_semaphore.release();
尝试获取信号量:
1
2
3
4
5if (my_semaphore.try_acquire()) {
// 成功获取信号量
} else {
// 获取信号量失败
}
示例代码
以下是一些使用不同环境中的信号量的示例代码。
Linux 内核中的信号量示例
1 |
|
POSIX 线程中的信号量示例
1 |
|
C++20 中的信号量示例
1 |
|
总结
信号量的API在不同的操作系统和编程环境中有所不同。在Linux内核中,信号量的API定义在<linux/semaphore.h>中;在POSIX线程中,信号量的API定义在<semaphore.h>中;在C++20标准库中,信号量的API定义在<semaphore>中。选择合适的信号量API取决于具体的编程环境和需求。信号量可以有效地控制对共享资源的访问,允许多个线程或进程同时访问,但数量受限于信号量的初始值。